
In the realm of synthesizing visual content to meet users’ needs, achieving precise control over the pose, shape, expression, and layout of generated objects is crucial. Traditional approaches to controlling generative adversarial networks (GANs) have relied on manual annotations during training or prior 3D models, but they often lack the flexibility, precision, and versatility required for diverse applications.
What is Drag Your GAN?
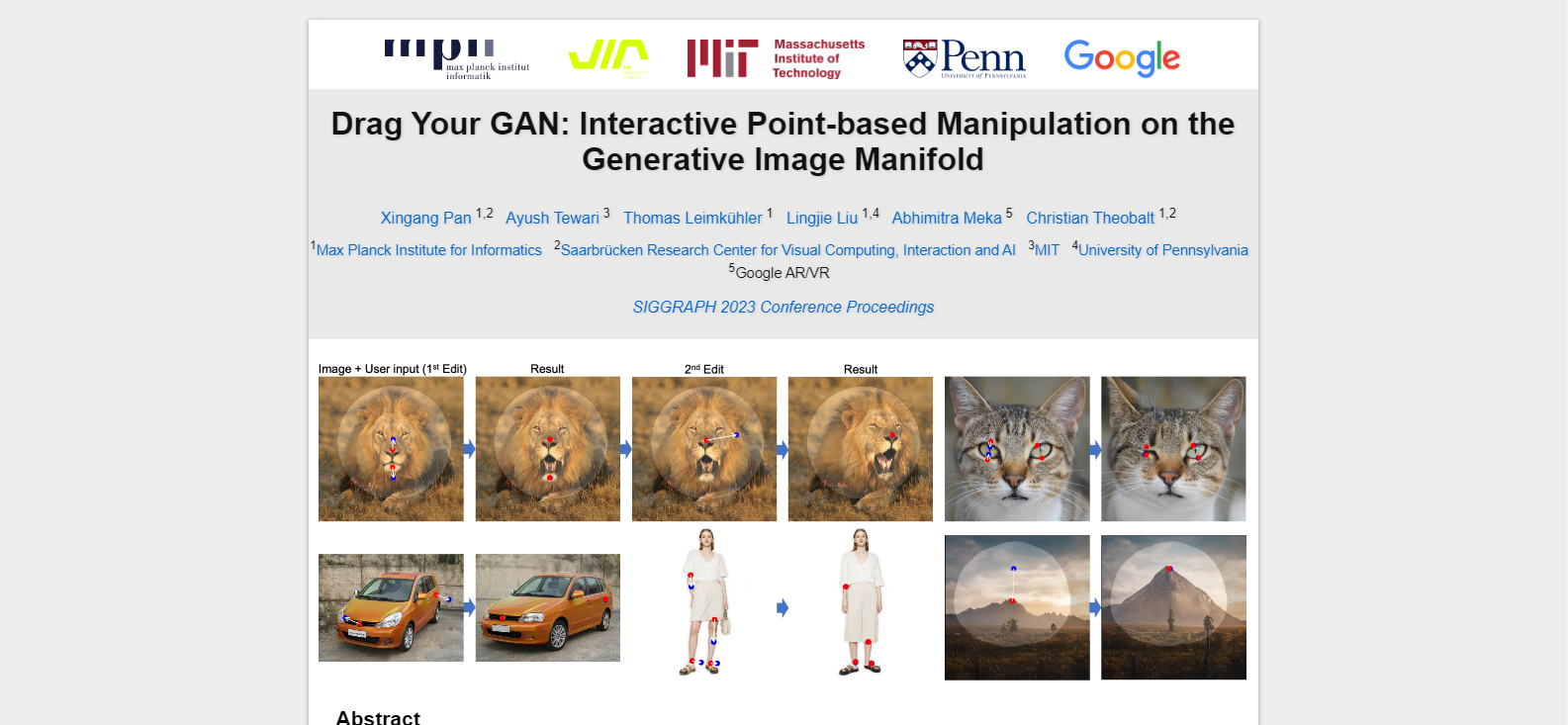
DragGAN empowers users to deform images with exceptional precision, allowing manipulation of the pose, shape, expression, and layout across various categories such as animals, cars, humans, landscapes, and more. These manipulations occur within the learned generative image manifold of a GAN, resulting in realistic outputs, even in complex scenarios like generating occluded content and deforming shapes while maintaining the object’s rigidity.
Our comprehensive evaluations, encompassing both qualitative and quantitative comparisons, highlight the superiority of DragGAN over existing methods in tasks related to image manipulation and point tracking. Furthermore, we demonstrate its capabilities in manipulating real-world images through GAN inversion, showcasing its potential for various practical applications in the field of visual content synthesis and control.
Our research delves into an innovative and relatively unexplored method for GAN control – the ability to “drag” specific image points to precisely reach user-defined target points interactively (as shown in Fig.1). This approach has led to the development of DragGAN, a groundbreaking framework consisting of two core components:
Key Features:
- Feature-Based Motion Supervision: This component guides handle points within the image toward their intended target positions using feature-based motion supervision.
- Point Tracking: Leveraging discriminative GAN features, our novel point tracking technique continuously localizes the position of handle points.